📝 LLM Research Journal Entry: [Experiment/Project Title]
Metadata
- Date: [YYYY-MM-DD]
- Paper: LoCoMo PDF
- Researcher(s): [Your Name(s)]
- LLM Model Used: [e.g., GPT-4, Llama 2 7B, Mistral 7B, etc.]
- Model Version/Fine-Tuning Details: [e.g., Base model, Instruct-tuned, Custom fine-tuning parameters]
- Task/Goal: [A concise statement of the experiment’s objective]
1. 🎯 Experiment Design & Methodology
Describe how the experiment was conducted, including the dataset and evaluation metrics.
- Hypothesis: [What did you expect to happen or what were you testing?]
- Dataset/Prompt Set:
- Source: [e.g., Custom generated, Open-source dataset like SQuAD, HELM]
- Size: [Number of samples/prompts]
- Preprocessing: [e.g., Cleaned, standardized, converted to specific format]
- Key Parameters (Inference Settings):
- Temperature: [e.g., 0.7, 0.0]
- Top-P/Top-K: [e.g., 0.9, 50]
- Max New Tokens: [e.g., 256]
- Prompting Technique: [e.g., Zero-shot, Few-shot (N=X examples), Chain-of-Thought (CoT)]
2. 📊 Results & Benchmarks
Present the quantitative and qualitative findings, focusing on key performance indicators (KPIs).
- Primary Metric: [e.g., F1 Score, Accuracy, Perplexity, Human Evaluation Rating]
- Value: [X.XX]
- Baseline (if applicable): [Y.YY]
- Secondary Metrics: * *
- Resource Utilization (For Local Models/Training):
- Inference Speed: [e.g., X tokens/second, Y milliseconds/query]
- Hardware Used: [e.g., NVIDIA A100 80GB, M2 Ultra]
- Peak Memory Usage: [Z GB]
DeepSeek Chat Gemini 2.5 Flash Qwen30b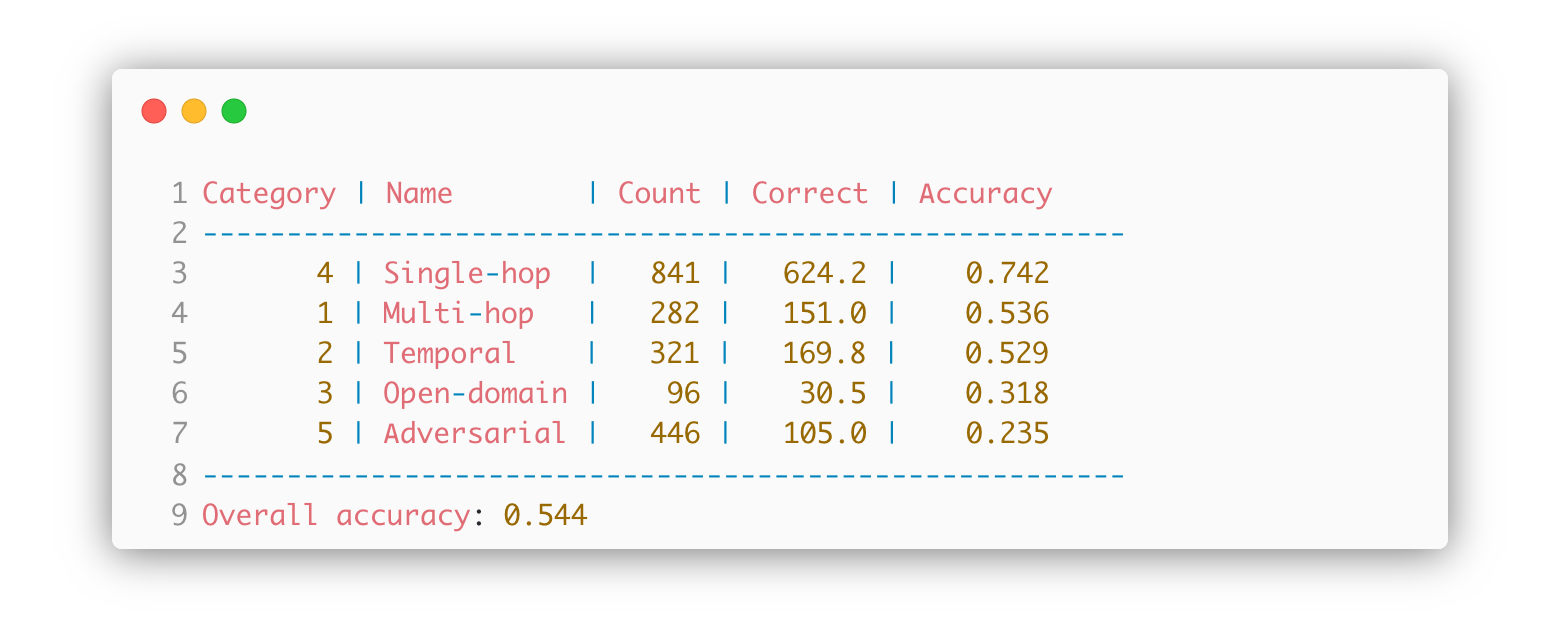
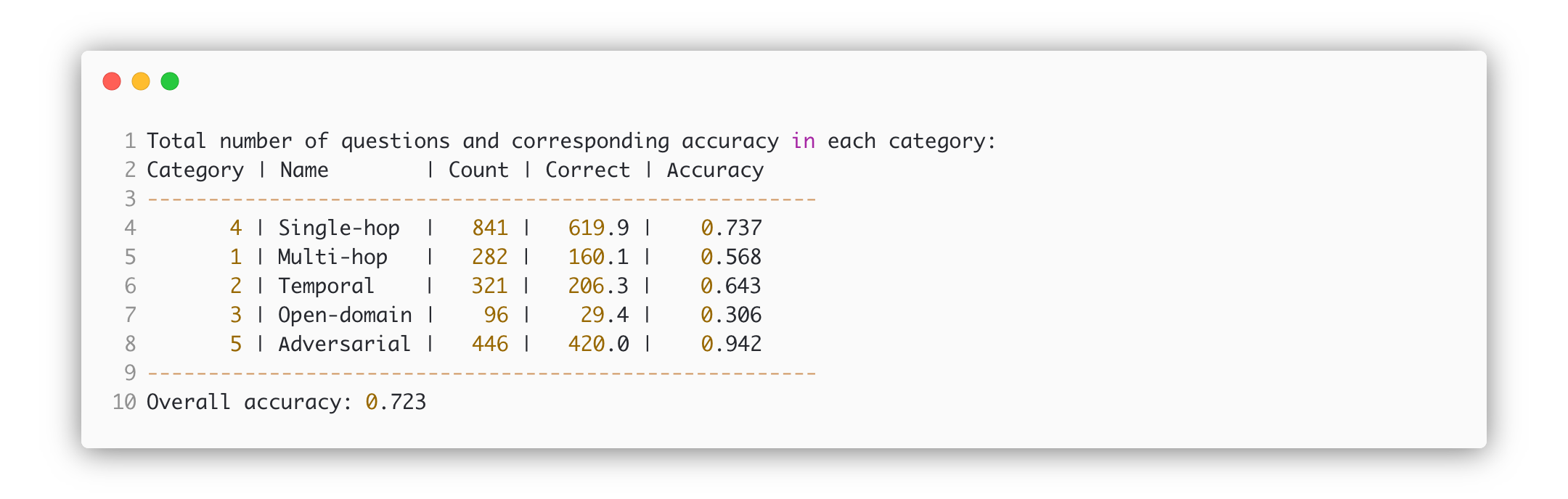
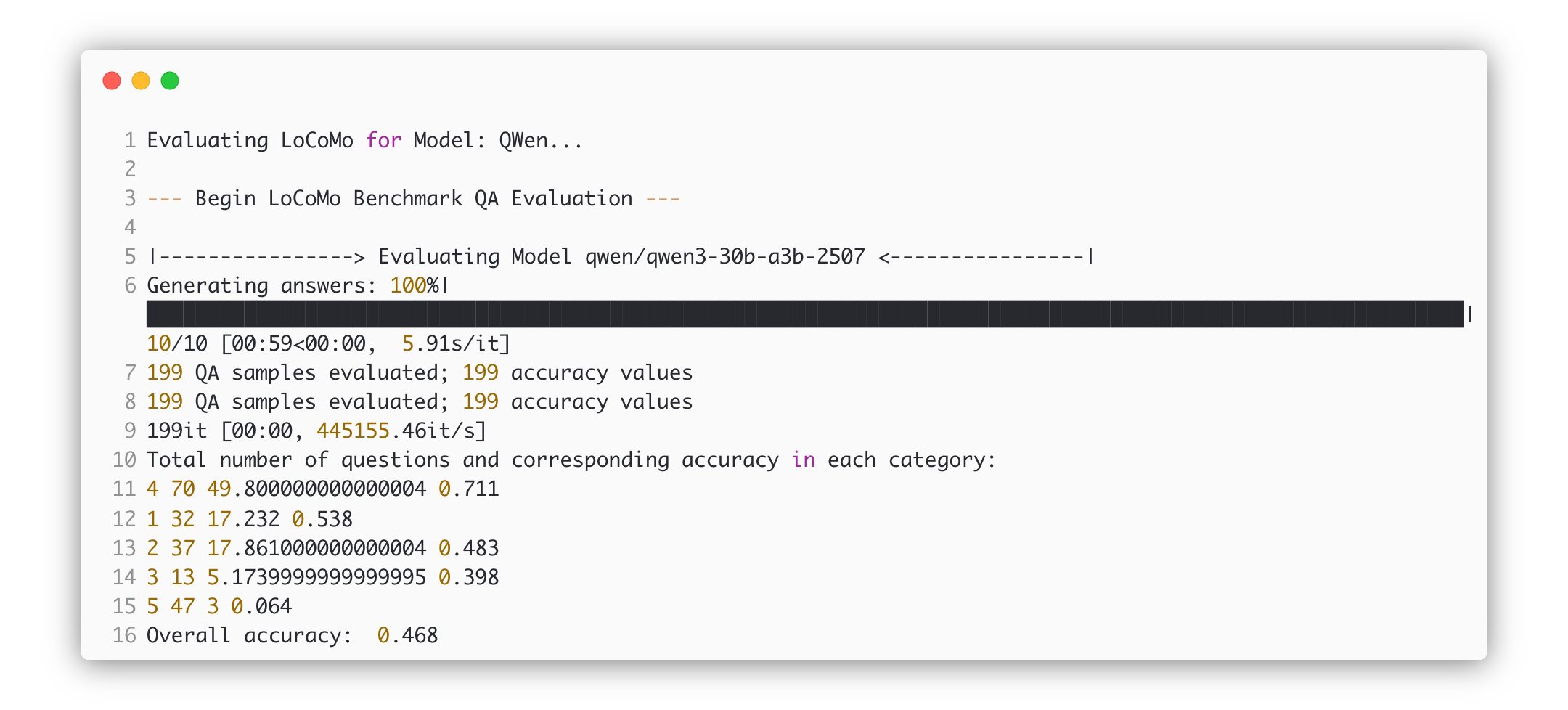
Table of Benchmarks (Comparison to other models/methods):
| Model/Method | Primary Metric Value | Inference Speed | Notes |
|---|---|---|---|
| [Current Experiment Model] | [X.XX] | [Y t/s] | [Key insight] |
| Previous Iteration/Model A | A.AA | B t/s | Different prompt technique |
| State-of-the-Art (SOTA) | S.SS | D t/s | For comparison |
3. 🔍 Analysis & Observations
Detail your qualitative experience, successes, and failures.
- Key Successes:
- [Point 1: What worked well? E.g., CoT significantly improved performance.]
- [Point 2: Unexpected positive findings.]
- Failure Modes / Errors:
- Common Error Type: [e.g., Hallucination of facts, formatting inconsistencies, refusal to answer]
- Example Prompt/Response: (Optional, for illustrating the failure)
- [Point 2: Specific constraints or limitations encountered.]
- Qualitative Observations (The “Feel” of the Model):
- [e.g., The model was very verbose, required extensive prompt engineering, showed a strong bias toward certain topics.]
4. ⏭️ Conclusion & Next Steps
Summarize the key takeaway and plan future work.
- Key Takeaway: [One sentence summary of the experiment’s most important result or insight.]
- Future Work / Recommendations:
- [Action 1: What should be tried next? E.g., Testing a higher temperature/sampling method.]
- [Action 2: Proposal for fine-tuning or model modification.]
- [Action 3: New metric or dataset to explore.]
5. 🔗 Artifacts & Resources
- Code Repository Link: [Link to GitHub, GitLab, etc.]
- Raw Data/Logs Link: [Link to a public or internal storage]
- Full Prompt Example:
[Insert a representative example of the system/user prompt used]